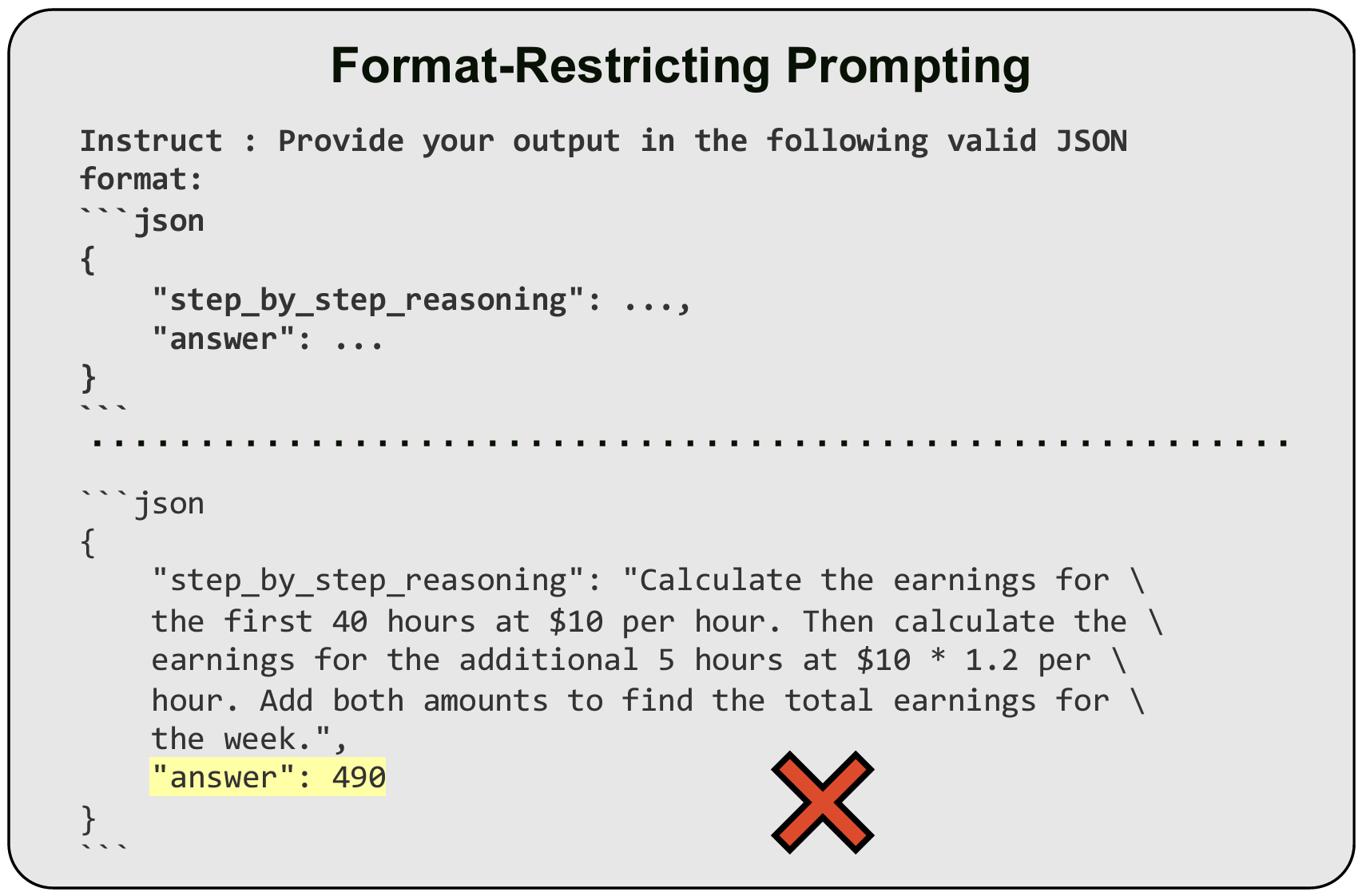
Structured generation, the process of producing content in standardized formats like JSON and XML, is widely utilized in real-world applications to extract key output information from large language models (LLMs). This study investigates whether such constraints on generation space impact LLMs abilities, including reasoning and domain knowledge comprehension. Specifically, we evaluate LLMs performance when restricted to adhere to structured formats versus generating free-form responses across various common tasks. Surprisingly, we observe a significant decline in LLMs reasoning abilities under format restrictions. Furthermore, we find that stricter format constraints generally lead to greater performance degradation in reasoning tasks.
@article{tam2024let,title={Let me speak freely? a study on the impact of format restrictions on performance of large language models},author={Tam, Zhi Rui and Wu, Cheng-Kuang and Tsai, Yi-Lin and Lin, Chieh-Yen and Lee, Hung-yi and Chen, Yun-Nung},journal={arXiv preprint arXiv:2408.02442},year={2024},}
EMNLP 2024
I Need Help! Evaluating LLM’s Ability to Ask for Users’ Support: A Case Study on Text-to-SQL Generation
Cheng-Kuang Wu*, Zhi Rui Tam*, Chao-Chung Wu, and 3 more authors
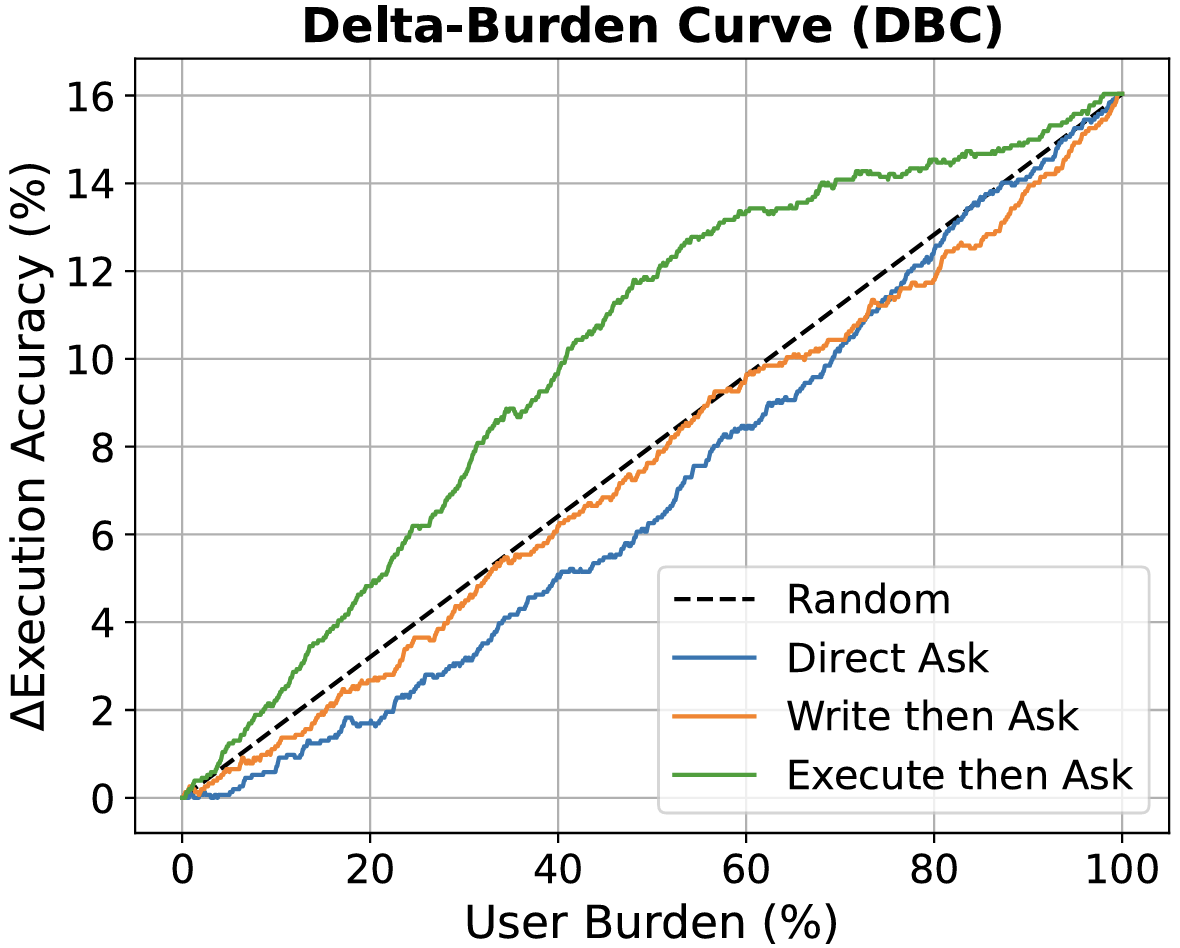
This study explores the proactive ability of LLMs to seek user support. We propose metrics to evaluate the trade-off between performance improvements and user burden, and investigate whether LLMs can determine when to request help under varying information availability. Our experiments show that without external feedback, many LLMs struggle to recognize their need for user support. The findings highlight the importance of external signals and provide insights for future research on improving support-seeking strategies.
@article{wu2024need,title={I Need Help! Evaluating LLM's Ability to Ask for Users' Support: A Case Study on Text-to-SQL Generation},author={Wu, Cheng-Kuang and Tam, Zhi Rui and Wu, Chao-Chung and Lin, Chieh-Yen and Lee, Hung-yi and Chen, Yun-Nung},journal={arXiv preprint arXiv:2407.14767},year={2024},}
NeurIPS 2024
StreamBench: Towards Benchmarking Continuous Improvement of Language Agents
Cheng-Kuang Wu*, Zhi Rui Tam*, Chieh-Yen Lin, and 2 more authors
arXiv preprint arXiv:2406.08747. NeurIPS 2024 (Datasets and Benchmarks) , 2024
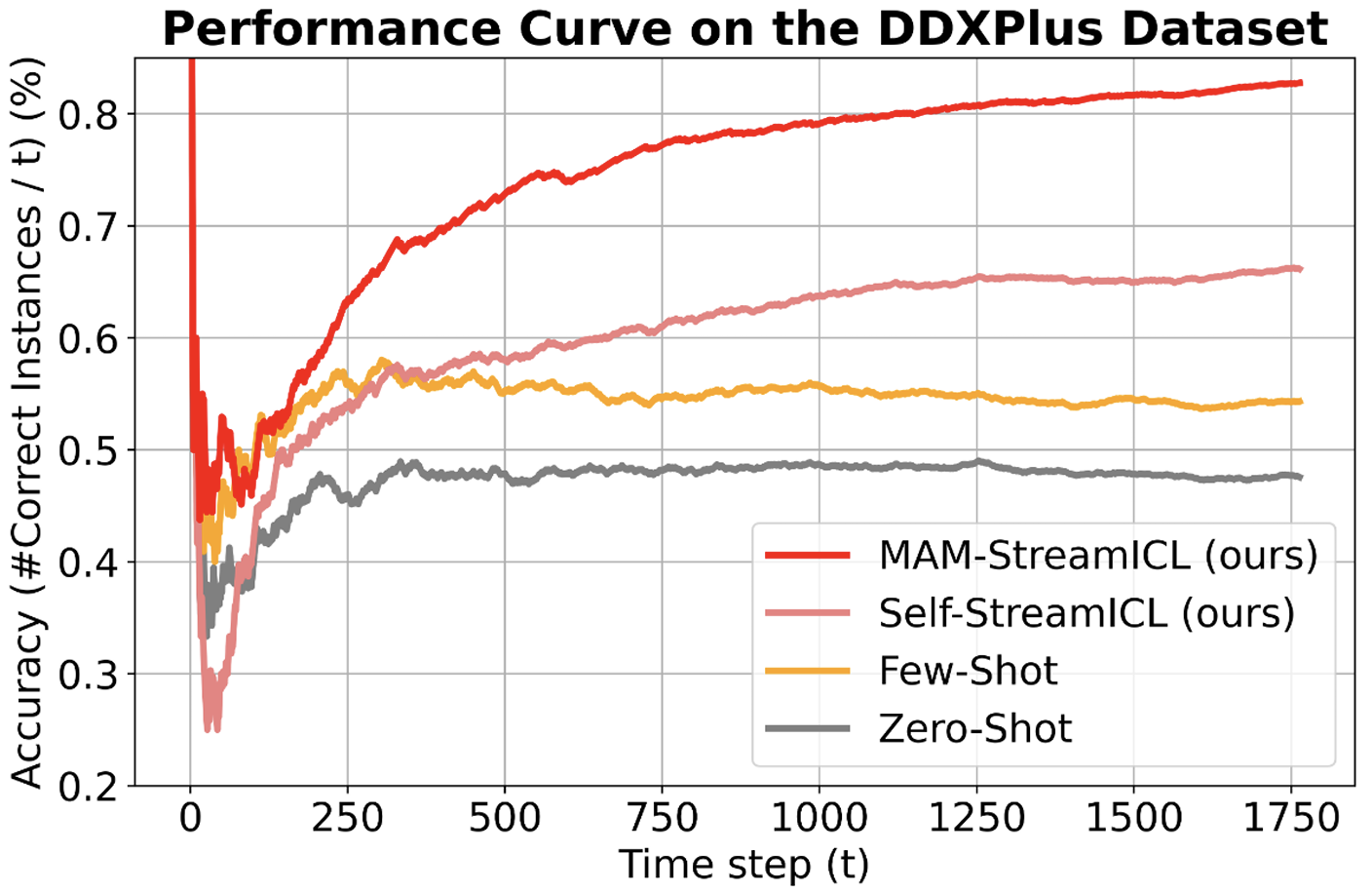
Recent works have shown that large language model (LLM) agents are able to improve themselves from experience, which is an important ability for continuous enhancement post-deployment. However, existing benchmarks primarily evaluate their innate capabilities and do not assess their ability to improve over time. To address this gap, we introduce StreamBench, a pioneering benchmark designed to evaluate the continuous improvement of LLM agents over an input-feedback sequence. StreamBench simulates an online learning environment where LLMs receive a continuous flow of feedback stream and iteratively enhance their performance. In addition, we propose several simple yet effective baselines for improving LLMs on StreamBench, and provide a comprehensive analysis to identify critical components that contribute to successful streaming strategies. Our work serves as a stepping stone towards developing effective online learning strategies for LLMs, paving the way for more adaptive AI systems in streaming scenarios.
@article{wu2024streambench,title={StreamBench: Towards Benchmarking Continuous Improvement of Language Agents},author={Wu, Cheng-Kuang and Tam, Zhi Rui and Lin, Chieh-Yen and Chen, Yun-Nung and Lee, Hung-yi},journal={arXiv preprint arXiv:2406.08747},year={2024},}
ACL 2024
Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models
Sheng-Lun Wei, Cheng-Kuang Wu, Hen-Hsen Huang, and 1 more author
In this paper, we investigate the phenomena of "selection biases" in Large Language Models (LLMs), focusing on problems where models are tasked with choosing the optimal option from an ordered sequence. We delve into biases related to option order and token usage, which significantly impact LLMs’ decision-making processes. We also quantify the impact of these biases through an extensive empirical analysis across multiple models and tasks. Furthermore, we propose mitigation strategies to enhance model performance. Our key contributions are threefold: 1) Precisely quantifying the influence of option order and token on LLMs, 2) Developing strategies to mitigate the impact of token and order sensitivity to enhance robustness, and 3) Offering a detailed analysis of sensitivity across models and tasks, which informs the creation of more stable and reliable LLM applications for selection problems.
@article{wei2024unveiling,title={Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models},author={Wei, Sheng-Lun and Wu, Cheng-Kuang and Huang, Hen-Hsen and Chen, Hsin-Hsi},journal={arXiv preprint arXiv:2406.03009},year={2024}}
2023
EMNLP 2023
Self-ICL: Zero-Shot In-Context Learning with Self-Generated Demonstrations
Wei-Lin Chen*, Cheng-Kuang Wu*, Yun-Nung Chen, and 1 more author
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
Large language models (LLMs) have exhibited striking in-context learning (ICL) ability to adapt to target tasks with a few input-output demonstrations. For better ICL, different methods are proposed to select representative demonstrations from existing training corpora. However, such settings are not aligned with real-world practices, as end-users usually query LMs without access to demonstration pools. In this work, we introduce Self-ICL – a simple framework which bootstraps LMs’ intrinsic capabilities to perform zero-shot ICL. Given a test input, Self-ICL first prompts the model to generate pseudo-inputs. Next, the model predicts pseudo-labels for the pseudo-inputs via zero-shot prompting. Finally, we perform ICL for the test input with the pseudo-input-label pairs as demonstrations. Evaluation on 23 BIG-Bench Hard tasks shows Self-ICL outperforms zero-shot baselines on both average accuracy and head-to-head comparison. Moreover, with zero-shot chain-of-thought, Self-ICL achieves results comparable to using real demonstrations. Additionally, we conduct a range of analyses to validate Self-ICL’s effectiveness and provide insights for its behaviors under different settings.
@inproceedings{chen2023self,title={Self-ICL: Zero-Shot In-Context Learning with Self-Generated Demonstrations},author={Chen, Wei-Lin and Wu, Cheng-Kuang and Chen, Yun-Nung and Chen, Hsin-Hsi},booktitle={Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing},pages={15651--15662},year={2023}}
EMNLP 2023
Fidelity-Enriched Contrastive Search: Reconciling the Faithfulness-Diversity Trade-Off in Text Generation
Wei-Lin Chen, Cheng-Kuang Wu, Hsin-Hsi Chen, and 1 more author
In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
In this paper, we address the hallucination problem commonly found in natural language generation tasks. Language models often generate fluent and convincing content but can lack consistency with the provided source, resulting in potential inaccuracies. We propose a new decoding method called Fidelity-Enriched Contrastive Search (FECS), which augments the contrastive search framework with context-aware regularization terms. FECS promotes tokens that are semantically similar to the provided source while penalizing repetitiveness in the generated text. We demonstrate its effectiveness across two tasks prone to hallucination: abstractive summarization and dialogue generation. Results show that FECS consistently enhances faithfulness across various language model sizes while maintaining output diversity comparable to well-performing decoding algorithms.
@inproceedings{chen2023fidelity,title={Fidelity-Enriched Contrastive Search: Reconciling the Faithfulness-Diversity Trade-Off in Text Generation},author={Chen, Wei-Lin and Wu, Cheng-Kuang and Chen, Hsin-Hsi and Chen, Chung-Chi},booktitle={Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing},pages={843--851},year={2023}}
EMNLP 2023
ZARA: Improving Few-Shot Self-Rationalization for Small Language Models
Wei-Lin Chen, An-Zi Yen, Cheng-Kuang Wu, and 2 more authors
In Findings of the Association for Computational Linguistics: EMNLP 2023, 2023
Language models (LMs) that jointly generate end-task answers as well as free-text rationales are known as self-rationalization models. Recent works demonstrate great performance gain for self-rationalization by few-shot prompting LMs with rationale-augmented exemplars. However, the ability to benefit from explanations only emerges with large-scale LMs, which have poor accessibility. In this work, we explore the less-studied setting of leveraging explanations for small LMs to improve few-shot self-rationalization. We first revisit the relationship between rationales and answers. Inspired by the implicit mental process of how human beings assess explanations, we present a novel approach, Zero-shot Augmentation of Rationale-Answer pairs (ZARA), to automatically construct pseudo-parallel data for self-training by reducing the problem of plausibility judgement to natural language inference. Experimental results show ZARA achieves SOTA performance on the FEB benchmark, for both the task accuracy and the explanation metric. In addition, we conduct human and quantitative evaluation validating ZARA’s ability to automatically identify plausible and accurate rationale-answer pairs.
@inproceedings{chen2023zara,title={ZARA: Improving Few-Shot Self-Rationalization for Small Language Models},author={Chen, Wei-Lin and Yen, An-Zi and Wu, Cheng-Kuang and Huang, Hen-Hsen and Chen, Hsin-Hsi},booktitle={Findings of the Association for Computational Linguistics: EMNLP 2023},pages={4682--4693},year={2023}}
ICLR 2023
Large language models perform diagnostic reasoning
We explore the extension of chain-of-thought (CoT) prompting to medical reasoning for the task of automatic diagnosis. Motivated by doctors’ underlying reasoning process, we present Diagnostic-Reasoning CoT (DR-CoT). Empirical results demonstrate that by simply prompting large language models trained only on general text corpus with two DR-CoT exemplars, the diagnostic accuracy improves by 15% comparing to standard prompting. Moreover, the gap reaches a pronounced 18% in out-domain settings. Our findings suggest expert-knowledge reasoning in large language models can be elicited through proper promptings.
@article{wu2023large,title={Large language models perform diagnostic reasoning},author={Wu, Cheng-Kuang and Chen, Wei-Lin and Chen, Hsin-Hsi},journal={arXiv preprint arXiv:2307.08922},year={2023},}